Single Table Design with DynamoDB
Intro
DynamoDB is one of the NoSQL databases if the NoSQL terminology is right way to declare it. Here’s you can find basic differences between NoSQL and SQL databases.

If we’re running OLTP applications which are mostly apps we build today, when the button gets clicked it interacts with the database. In this case NoSQL can be a good choice because it’s optimized for the compute and scalable.
Background on SQL modeling & joins
With relational databases, you generally normalize your data by creating a table for each type of entity in your application. For example, if you’re making an e-commerce application, you’ll have one table for customers and one table for Orders.
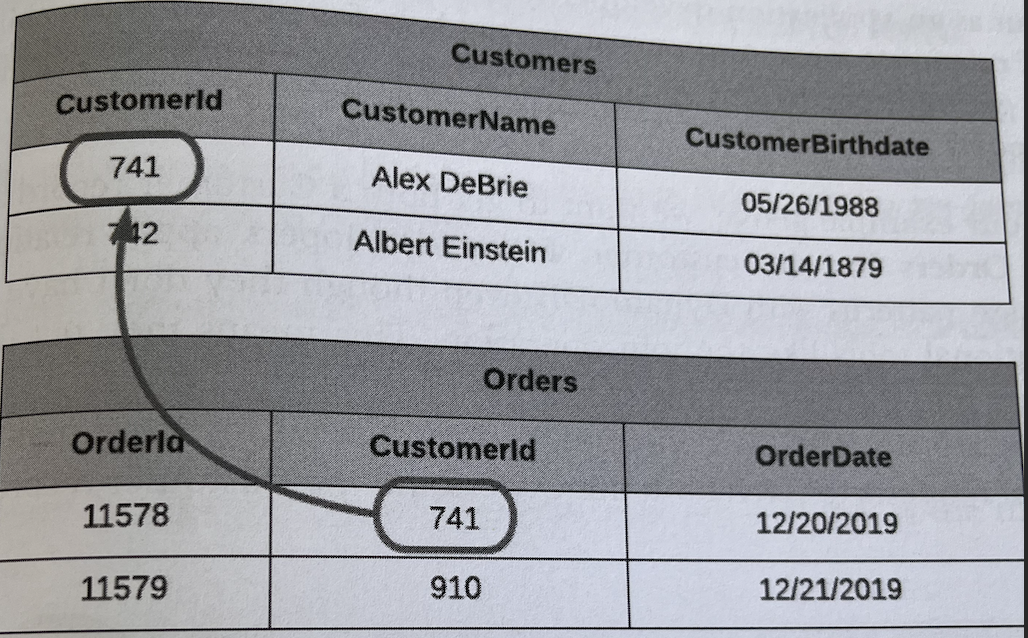
Each Order belongs to a certain Customer(add. benefits [Insertion,Update,Delete anomalies]), and you use foreign keys to refer from a record in one table to a record in another. These foreign keys act as pointers – If I need more information about a Customer that placed a particular Order, I can follow the foreign key reference to retrieve items about the Customer.
Joins allow you to combine records from two or more tables at read-time.
DynamoDB
DynamoDB is a fully managed AWS product for NoSQL database.
There are no joins in DynamoDB
SQL joins are also expensive (think these are memory pointers). They require scanning large portions of multiple tables in your relational database, comparing different values, and returning a result set.
DynamoDB closely guards against any operation that won’t scale, and there’s not a great way to make relational joins scale. Rather than working to make joins scale better, DynamoDB sidesteps the problem by removing the ability to use joins at all.
There’re no joins in DynamoDB. There’s a need to make multiple, serial requests to fetch both the Orders and the Customer record.
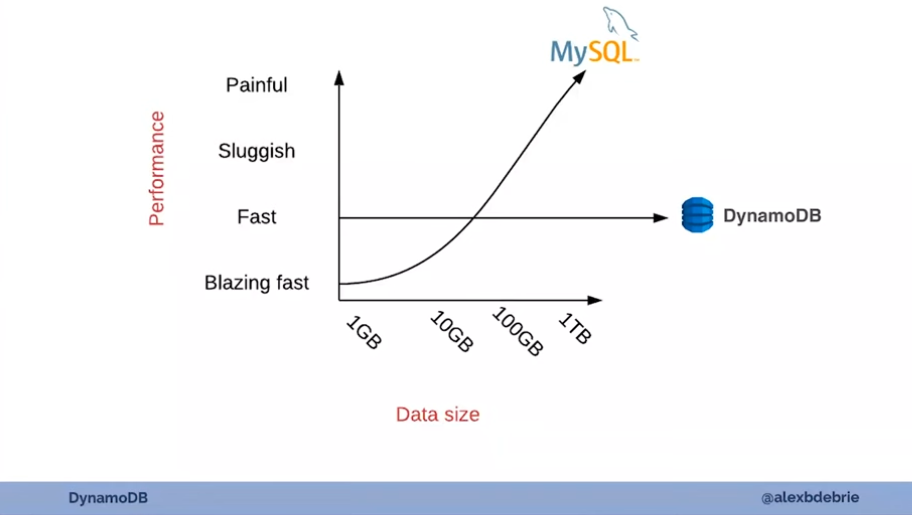
Joins are not scalable when the data grows: Link
The solution: Pre-join your data into item collections and Single Table Design
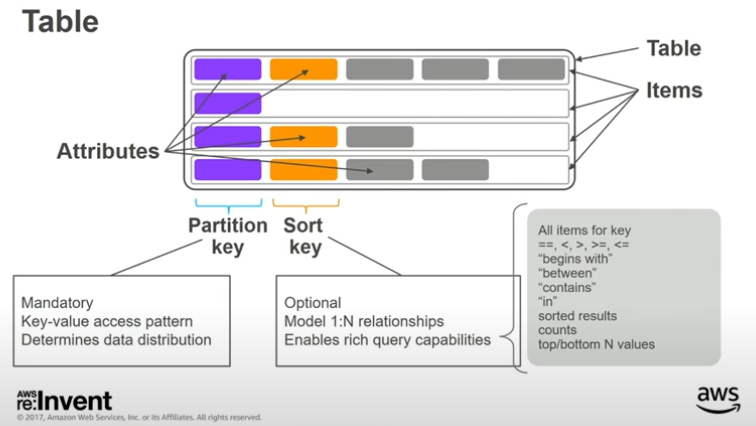
An item collection in DynamoDB refers to all the items in a table or index that share a partition key. In the example below, we have a DynamoDB table that contains actors and the movies in which they have played. The primary key is a composite primary key where the partition key is the actor’s name and the sort key is the movie name.
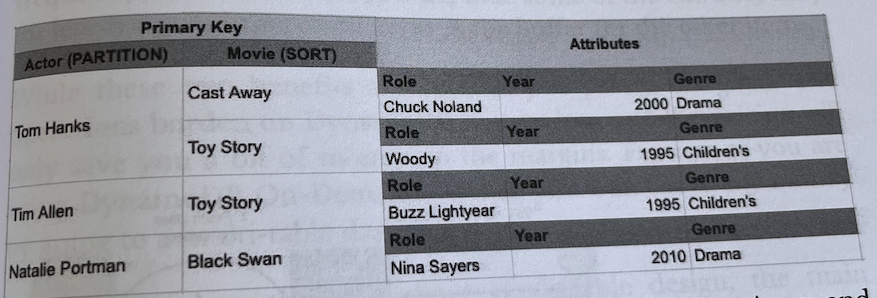
You can see there are two items for Tom Hanks - Cast Away and Toy Story. Because they have the same partition key of Tom Hanks. They are in the same item collection. Another example:

You can use DynamoDB’s Query API operation to read multiple items with the same partition key. Thus, if you need to retrieve multiple “heterogeneous” items in a single request, you organize those items so that they are in the same item collection.
This is what single-table design is all about - tuning your table so that your access patterns can be handled with as few requests to DynamoDB as possible, ideally one.
Downsides of a single-table design
- The steep learning curve to understand single-table design.
- The inflexibility of adding new access patterns. If your access patterns change because you’re adding new objects or accessing multiple objects in different ways, you may need to do an ETL process to scan every item in your table and update it with new attributes. This adds friction to your development process.
- The difficulty of exporting your tables for analytics. DynamoDB is designed for online transactional processing (OLTP), but the DynamoDB is not good at OLAP queries. This is intentional.
Simple Twitter data modelling demo and project link
Check out the demo for more info.